Background¶
Notation¶
The following basic notation will be used throughout.
\(d\): dimension;
\(\mathfrak{X} \subset \mathbb{R}^d\): feasible domain;
\(\lambda_{\max}\): maximal eigenvalue of a positive definite matrix;
\(\| \cdot \|\): Euclidean norm of a vector in \(\mathbb{R}^d\);
\(N\): total number of starting points;
\(X = {x_1,x_2,\ldots,x_N}\): a sequence of points in \(\mathfrak{X}\);
\(x_n=x_n^{(0)} \in X\), where \(n=1,2, \ldots N\): point chosen from \({X}\);
\(x_n^{(k)}\): the \(n\)-th point after \(k\) iterations of anti-gradient descent;
\(x_n^{(K_n)}\): smallest \(k=K_n\) such that \(\| \nabla f(x_n^{(k)}) \| < \delta\);
\(f(x_n^{(k)})\): objective function at \(x_n^{(k)}\);
\(\nabla f(x_n^{(k)})\): gradient of \(f\) at \(x_n^{(k)}\);
anti-gradient descent iteration:
\(\gamma_n^{(k)}\): step size for an anti-gradient descent iteration (1). Note that \(\gamma_n^{(k)} \geq 0\);
partner point:
\(\beta\) : small positive constant used as the step size for a parnter point (2);
\(\delta\) and \(\eta\): small positive constants;
\(M\): the minimum number of anti-gradient descent iterations (1) applied at each initial point \(x_n=x_n^{(0)}\) where \(n=1,2, \ldots, N\);
\(l\): index for the local minimizers \(l=1,\ldots,L\), where \(L\) is the total number of local minimizers found so far;
\(A_l\): \(l\)-th region of attraction;
\(x_l^{(K_l)}\): \(l\)-th local minimizer.
Main Conditions of the METOD Algorithm¶
The first main condition of the METOD Algorithm tests the following condition for each \(l=1,\ldots,L\) and all \(i=M-1,\ldots,K_l\)
For a given \(l\), if condition (3) holds for all \(i=M-1,\ldots, K_l\), then it is possible \(x_n\) belongs to \(A_l\), the same region of attraction corresponding to \(x_l^{(K_l)}\), and we terminate anti-gradient descent iterations (1). Let \(S_n\) be the set of indices \(l\), such that \(x_n\) may belong to region of attraction \(A_l\). If condition (3) holds, we add index \(l\) to the set \(S_n\).
If condition (3) does not hold for a point \(x_n\) with any \(l=1,\ldots,L\), then we apply anti-gradient descent iterations (1) until a minimizer \(x_n^{(K_n)}\) is found. However, we may have that minimizer \(x_n^{(K_n)}\) has already been discovered. As a consequence, the second main condition of the algorithm is to ensure that all discovered local minimizers are unique. To return unique local minimizers only, the following condition is tested for all \(i=1,\ldots,L\) and \(j=i + 1,\ldots,L\)
If condition (4) fails for any \(j\), then minimizers \(x_i^{ (K_i)}\) and \(x_j^{(K_j)}\) are the same and \(j\) is removed from the set of indices \(l=1,\ldots,L\).
METOD Algorithm¶
The METOD Algorithm can be split into the following three parts.
Initialization
Terminate anti-gradient descent iterations for \(n\)-th point.
For \(n=2\) to \(N\)
Choose \(x_n=x_n^{(0)} \in {X}\). Compute \(x_n^{(j)}\) for \(j=1, \ldots, M\) and the associated partner points using (2).
For \(l=1\) to \(L\)
To get to this stage, \(S_n\) must be empty. Hence, let \(x_{L+1} = x_n\) and continue iterations (1) until a minimizer \(x_{L+1}^{(K_{L+1})}\) is found.
For all points \(x_{L+1}^{(k)}\) \(k =M-1, \ldots, K_{L+1}\), compute the associated partner points using (2) and set \(L \gets L+1\).
Return unique minimizers from Step 2.
For \(i=1\) to \(L\)
For \(j=i+1\) to \(L\)
If condition (4) is not satisfied for \({x}_{i}^{(K_i)}\) and \({x}_{j}^{(K_j)}\)
Remove index \(j\) from the set of indices \(l=1,\ldots,L\).
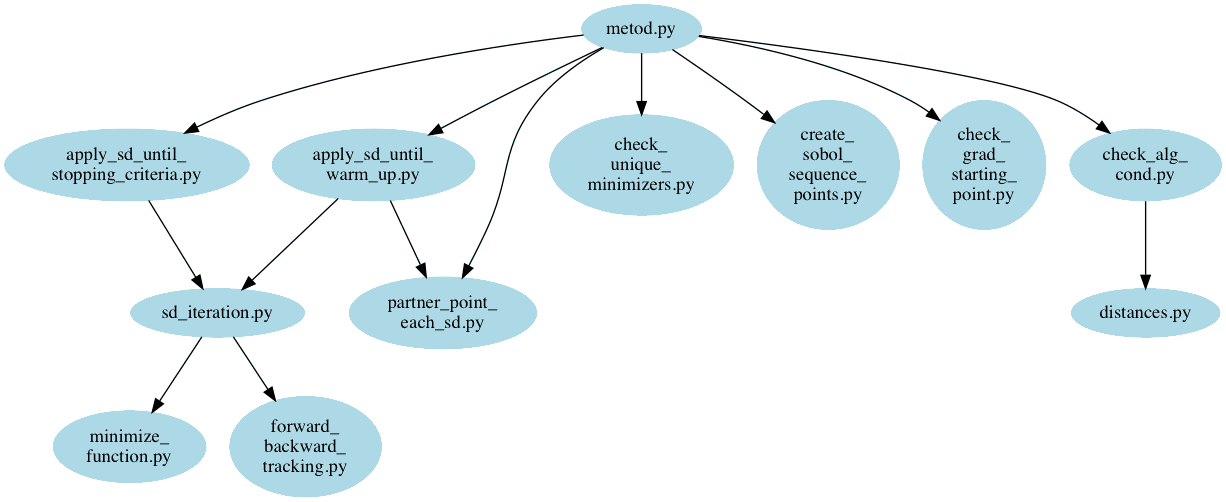
Code Structure¶
The METOD Algorithm code can be found here. The main program that executes the METOD Algorithm is metod.py and the following diagram shows the various programs that contribute to metod.py.